On a solid ground. Building software for a 120-year-old research project applying modern engineering practices

There is no doubt that the increasing use of digital methods and tools in the humanities opens up an almost infinite number of new possibilities. At the same time, it is becoming more and more clear that this creates new problems for the humanities. Many software solutions are often ‘quick hacks’—changes to them are time-consuming, lead to errors, and the sustainability of the solution itself is overall questionable. Digital editing projects—which are mostly based on TEI-XML—face this challenge from the beginning: The ‘TEI standard’ is rather a loose collection of recommendations, which necessitates the development of a customized schema (a TEI subset) for project-specific data, so that the edition or encoding guidelines can be enforced and their compliance checked. These machine-readable rules must be supplemented by human-readable guidelines which document the fundamental philological decisions and can be used as a manual for the editors.
The development of such a schema—and the associated workflows—becomes particularly relevant in the context of long-term projects, such as the Collection of Swiss Legal Sources (SLS). Changes to the schema require a continuous conversion of existing datasets. The contribution addresses how practices of modern software development, such as versioning or test-driven development (TDD), can be profitably used for humanities projects. It presents the entire workflow beginning with the creation of a modularized schema for a complex text corpus, which includes texts in German, French, Latin, Italian and Romansh from the 6th to the 18th century, up to the automated verification and publication of the documentation/schema.
software engineering, TEI-XML, digital edition, project organization
Introduction
General Problem Description
Nowadays, software is a central component of every research project. Since the establishment of personal computers digital tools are used for a wide range of tasks, from simple text processing to machine assisted recognition in all sorts of historical documents. Research projects however, in particular those that produce digital scholarly editions, rarely rely just on existing tools, they often create new ones. Starting from the development or customization of own data formats ending with the implementation of often complex web applications for presentation, it is not uncommon for the tools developed in this context to be ‘quick hacks’ rather than well-designed software projects.1 In many cases, this is not a problem at all, because the duration of research projects in the humanities is often rather short (e.g. between three and six years). Software developed in such a short amount of time must first and foremost achieve the project’s goals, and therefore adaptation to other subjects or subsequent use is usually not intended. However, this becomes a problem if the corresponding research project is scheduled for a longer term, or if it is part of a series of projects depending on each other. In this case, quick solutions often become serious issues and are not really FAIR for either internal or external subsequent use. Not least for this reason, this phenomenon is the subject of discussion in the digital humanities community under the heading of research software engineering.2 This paper describes practical experiences from the perspective of a long-term editorial project and explores opportunities for sustainable development practices by utilizing modern methods that have long been established outside the academic world.
The Swiss Law Sources
The Collection of Swiss Law Sources (SLS) is a 120 year old research project that publishes Swiss legal texts in German, French, Latin, Italian and Romansh from the 6th to the 18th century. The edited texts are published in a printed reference publication and in digital form.3 By the time of writing ten edition projects are currently carried out by 23 researchers in three languages throughout Switzerland: In French, volumes are to be published in the cantons of Geneva (1 vol.), Vaud (2 vols.) Neuchatel (1 vol.), Fribourg (1 vol.); in German Valais (1 vol.), Lucerne (2 vols.), Schaffhausen (2 vols.), St. Gallen (1 vol.), Graubünden (1 vol.) and in Italian Ticino (1 vol.). Further editions projects are planned or applied for, while the overall project is scheduled for another ~ 50 years. The entire technical infrastructure is provided and developed by the SLS core team, which consists of the project manager and two members of staff specializing in DH (the authors of this paper). This team is also responsible for coordinating the projects, processing the data, typesetting the printed volumes and digital publishing of the edited texts.
In this context, the development of new and the improvement of already existing software is not only a technical challenge, but also an organizational one. Existing applications must run continuously to provide the researchers with the tools they need for their daily work (and to grant the users of the digital edition access to all information), while new requirements must be met on an ongoing basis as each project deals with unique documents.
Sidenote on the evolution technical infrastructure of the SLS
About 15 years ago the Swiss Law Foundation, which stands behind the SLS, decided to retro-digitize the over hundred volumes published up to that point. Since then, the results of these initial digitization efforts have been presented in a web application which, as a ‘browsing machine’, makes the results of the many years of editing work, previously locked between two book covers, available to a broad public. This also marked the start of the project’s transition to a predominantly digital editing and working method. In these 15 years numerous (web) applications have been created: These include databases that collate information on historical entities (people, organizations, places and terms), a digital application that presents the transcriptions, now encoded in TEI-XML, in both a web and a print view and a lot of other tools used in the various tasks at hand. The ongoing nature of the project was one of the reasons why many of these applications were often ‘ad hoc solutions’ or proof of concepts that were neither designed for long-term operation nor for integration—i.e. collaboration—with other tools. As a result, a rather diverse ecosystem of different technologies has developed on the data side and on the processing and presentation side.4
Data as a solid ground: developing an XML Schema for a scholarly edition
The foundation of a digital scholarly edition is undoubtedly the transcribed and annotated data, which usually is encoded in an XML format.5 All our newly edited texts are encoded in XML and as time permits all previously edited texts will be converted to this format. Therefore all further application layers, such as web presentation or printed output, have to be based on these XML files according to the single source principle. Over the last two decades, the guidelines of the Text Encoding Initiative (TEI)6 have established themselves as the de facto standard for this markup work. These guidelines are primarily a broad collection of suggestions rather than a clear set of rules, necessitating a precise formulation of philological concepts into a logical data model, specifically the creation of a TEI subset as an XML schema. The TEI itself offers a format called ODD (One Document Does it all) for creating an XML schema in a literate programming-fashion7, which itself is TEI-XML.8
A schema’s main use case is validation, i.e. checking whether the XML data corresponds to certain structures and constraints. As a TEI subset it defines which components and elements provided by the TEI guidelines are used and how they are used, making it an important part of the editing concept itself. The validation against a schema ensures the consistency of the resulting data sets in an ongoing project and is necessary to continuously support and check the researchers during the transcription and annotation process. Therefore we regard an XML schema as a key software component, although the development of a schema is typically not understood as software development in the true sense of the word. This is probably one of the reasons why most of the modern engineering practices we want to demonstrate are not yet applied in this field (at least as far as we know).
Four modern engineering practices and their application
In order to deal with a complex situation, as described above, the authors of this paper propose to make use of the following software engineering practices9:
- modular software development
- test driven development
- semantic versioning
- semiautomatic documentation
The development of the XML schema used in our project will be used as an example to show how these practices can be utilized for digital humanities projects. In the context of the ongoing reworking of the SLS application landscape, we developed a test based and modular workflow (see Figure 1) for the creation of a new schema, based on ODD-files as input.10
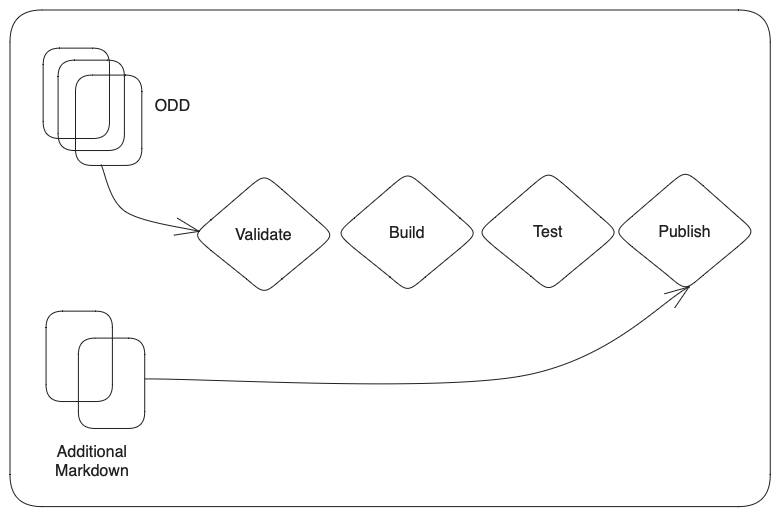
Modular software development
If you download a sample ODD file from the TEI homepage11 which contains all elements and components, such a file may be made up of 70000 lines of code. Our ODD file—which is just a limited subset—still contains way over 20000 lines of code. The first step to handle such a large and complex object is to split it into manageable pieces. For each TEI-element we need, we created a separate file containing the element’s specification. Common parts like attribute classes, data types or custom definitions that are used by multiple elements each went into their own files.
A rather simple specification for the element <pc/> may look like this:
<elementSpec
xmlns="http://www.tei-c.org/ns/1.0" xmlns:rng="http://relaxng.org/ns/structure/1.0" ident="pc" module="analysis" mode="change">
<desc xml:lang="en" versionDate="2024-04-30">
Contains a punctuation mark, which is processed specially
considering linguistic regulations (for example, by adding a space).
</desc>
<classes mode="replace"/>
<content>
<rng:data type="string">
<rng:param name="pattern">[;:?!]</rng:param>
</rng:data>
</content>
<attList>
<attDef ident="force" mode="delete"/>
<attDef ident="unit" mode="delete"/>
<attDef ident="pre" mode="delete"/>
</attList>
</elementSpec>This principle of atomicity enforces a clear structure, provides better maintainability in the future, made the files way more easy to grasp and to modify and had also the benefit of reducing redundancy, because shared parts were refactored and can be used throughout the schema while being defined in one place. The downside to this, of course, is the need to compile all those files into one ODD in a separate step. But this may be a small price to pay for the benefits.
Test driven development (TDD)12
The second step was to define a set of tests for all element, attribute and datatype definitions.13 Each test set describes the expected behavior of a piece of the schema and consists of three components: a title of the test set, the markup being tested and the expected result, which can either be valid (True) or invalid (False). Each test set is executed and evaluated by a Python function which invokes an XML-Parser.
The following tests describe the contents and attributes of the element <pc/>.
@pytest.mark.parametrize(
"name, markup, result",
[
(
"valid-pc",
"<pc>;</pc>",
True,
),
(
"invalid-pc-with-wrong-char",
"<pc>-</pc>",
False,
),
(
"invalid-pc-with-attribute",
"<pc unit='c'>;</pc>",
False,
),
],
)
def test_pc(
test_element_with_rng: RNG_test_function,
name: str,
markup: str,
result: bool,
):
test_element_with_rng("pc", name, markup, result, False)If each specification is coupled with one or more tests, it is guaranteed that individual changes to the schema will not compromise the overall functionality and possible side-effects may be detected early on. Such test cases are abstract enough to enable representative testing of the software components to be developed, but at the same time concrete enough to make them readable for employees specializing in philology, thus they can be used as a means of communication between the digital humanist team and the philological or historical team. We can simply ask: Should this piece of XML be True or False?
Semiautomatic documentation
The schema has to be documented for those who use it to encode the files as well as for those who use the files for any other purpose. We decided to generate as much of this documentation automatically as possible using markdown as a language and a site generator called MkDocs14. Our documentation website15 is constructed like this: A self written Python program reads all parts of the schema, converts them to markdown files and hands those to the MkDocs processor which returns a static HTML webpage that can easily be accessed and searched.
Semantic versioning (SemVer and git)
It is obvious that each change to the schema not only affects the XML files to be validated16, but also changes the documentation. For this purpose every release of the schema is versioned with git and is reflected in a new corresponding build of the documentation site. All versions of the schema are named in accordance to the principles of semantic versioning17 so a user of any XML file that has to be validated against our schema can see which versions are available and is able to read a specific documentation for any schema version.
A brief outlook
Although our journey of refactoring has just begun, we are already seeing the benefits of the principles we have applied. If the ground your are standing on is a solid one, you can build on it. Currently, we are working on a multilingual translation of our schema from German as the main language to English, French and Italian and hope to enrich the schema with extensive examples from actual XML files. Furthermore, we are rewriting the existing rendering-mechanisms (e.g. TEI to HTML), applying the same rules as described above. All in all, the work done and the cost we had to pay for is already paying off.
References
Footnotes
Carver et al. recently demonstrated this with a survey, which shows that many researchers developing software have never received training in software development, and best practices are often ignored. See Carver et al. (2022).↩︎
See Manuel Burghardt and Claudia Müller-Birn organised a workshop specifically on this topic at the 50th Annual Conference of the German Informatics Society, see Burghardt and Müller-Birn (2019).↩︎
See Law Sources Foundation of the Swiss Lawyers Society (2024a) for the web presentation.↩︎
The edited texts themselves are available as PDF (the retro-digitized collection), TeX and FileMaker (transition phase) and TEI-XML (current projects). These are processed by scripts and applications in the programming languages Perl, OCaml, Python, JavaScript and XQuery. Relational as well as graph-based and document-orientated databases are used to store the entity data.↩︎
There have been various discussion what’s the key value of a digital scholarly digition. Maybe it’s the data (see Porter (2024)) or it’s the interface (see Zundert and Andrews (2018)). In the recent time it’s becoming more and more clear, it could be both. Therefore models have been developed, which understand scholarly editions as a stack of data, the processing applied to it and the resulting presentation (see Neuber (2023), p. 71).↩︎
The term literate programming usually refers to a programming paradigm introduced by Donald E. Knuth. It describes an approach where programming is done in a human readable style at first. See Knuth (1992).↩︎
The ODD-format is used in various contexts, e.g. the German Textarchiv (DTA) uses ODD-files as a source for their TEI-subset DTABf. See Haaf and Thomas (2016).↩︎
This principles have been described in various books by many authors; one of the most famous is the book Clean code by Robert C. Martin (2009).↩︎
The source code of this pipeline as well as the ODD sources are open sourced and can be found in the corresponding GitHub-Repo as well as on Zenodo. See Politycki, Sonder, and Sutter (2024).↩︎
The starting point for the creation of ODD files is usually a tool called Roma. See Text Encoding Initiative (2024b).↩︎
The term TDD usually refers to Kent Beck, who reintroduced this idea in the early 2000s. It describes a programming paradigm where tests are written before the actual code. See Alsaqqa, Sawalha, and Abdel-Nabi (2020), p. 255.↩︎
These tests would normally be set up before the concrete description in the ODD-module is created, but we started with an already existing schema and decided to add the test later on.↩︎
See Law Sources Foundation of the Swiss Lawyers Society (2024b).↩︎
It may sometimes be necessary to convert them with XSLT to be valid against the newer version of the schema.↩︎
Reuse
Citation
@misc{sonder2024,
author = {Sonder, Christian and Politycki, Bastian},
editor = {Baudry, Jérôme and Burkart, Lucas and Joyeux-Prunel,
Béatrice and Kurmann, Eliane and Mähr, Moritz and Natale, Enrico and
Sibille, Christiane and Twente, Moritz},
title = {On a Solid Ground. {Building} Software for a 120-Year-Old
Research Project Applying Modern Engineering Practices},
date = {2024-07-25},
url = {https://digihistch24.github.io/book-of-abstracts/submissions/427/},
langid = {en},
abstract = {There is no doubt that the increasing use of digital
methods and tools in the humanities opens up an almost infinite
number of new possibilities. At the same time, it is becoming more
and more clear that this creates new problems for the humanities.
Many software solutions are often “quick hacks”—changes to them are
time-consuming, lead to errors, and the sustainability of the
solution itself is overall questionable. Digital editing
projects—which are mostly based on TEI-XML—face this challenge from
the beginning: The “TEI standard” is rather a loose collection of
recommendations, which necessitates the development of a customized
schema (a TEI subset) for project-specific data, so that the edition
or encoding guidelines can be enforced and their compliance checked.
These machine-readable rules must be supplemented by human-readable
guidelines which document the fundamental philological decisions and
can be used as a manual for the editors. The development of such a
schema—and the associated workflows—becomes particularly relevant in
the context of long-term projects, such as the Collection of Swiss
Legal Sources (SLS). Changes to the schema require a continuous
conversion of existing datasets. The contribution addresses how
practices of modern software development, such as versioning or
test-driven development (TDD), can be profitably used for humanities
projects. It presents the entire workflow beginning with the
creation of a modularized schema for a complex text corpus, which
includes texts in German, French, Latin, Italian and Romansh from
the 6th to the 18th century, up to the automated verification and
publication of the documentation/schema.}
}