AI-assisted Search for Digitized Publication Archives
Fostering the study of historical figures through the use of Natural Language Processing (NLP) and data visualization techniques

Historians typically navigate digital archives to find key figures (people, institutions, etc.) and understand the impact of their actions on history. However, cultural digital archives, relying on keyword-based search methods, often can yield numerous but imprecise results about key figures across various sources. This makes it difficult for historians to comprehend the chronological and contextual facts around a historical figure. Mini-Muse is a preliminary research project aimed at identifying data visualization models and user interface features that help researchers and students of history explore historical figures and their actions in context. The project leverages Natural Language Processing (NLP) algorithms and data visualization techniques. NLP algorithms extract metadata from unstructured text and generate structured data about key figures. Data visualization techniques further assist by enabling visual analysis of each figure’s timeline and its relationships. The project adopts a user-centred design approach to ensure that the AI-assisted search system meets the needs of historians. Preliminary analysis of the gathered results suggests that the introduction of an “action flow view”, a user interface that provides interactive timelines displaying historical figure’s actions, holds great promise.
Natural Language Processing, Text Summarization, Data Visualization, Visual Analysis, Interactive Timeline
Introduction
Cultural digital archives are a goldmine of information for historians, offering access to digitized sources online. However, research highlights that these archives often struggle with usability issues (Vora, Komura, and Stanton Usability Team 2010; Dani et al. 2015) including difficulties in accessing certain items and information. Moreover, several emerging challenges are affecting the work of historians. Among these are the limited ways to explore archives, because cultural digital archives typically rely heavily on keyword-based search methods, the lack of transparency about how search results are generated, and the absence of advanced search and filtering options to reduce the volume of search results. In recent years, several researches from both the computer science and information visualization domains have been conducted to investigate more advanced and easy-to-use methods to access digitized publications. In the computer science domain, studies on the recognition and classification of named entities are relevant for historians and scholars in general because they allow the search, retrieval and comparison of information (Meroño-Peñuela et al. 2014). However, it is necessary to overcome the current technical issues, including the reduction of the noisy OCR outputs, the lack of resources for the training of the algorithms and the dynamics of language (spelling variations and name irregularities) (Ehrmann et al. 2023).
In the information visualization domain, the concept of “generous interfaces” was introduced (Whitelaw 2015) to identify a design approach for cultural digital collections that focuses on providing broader, more engaging and multi-faceted views on the content through the use of the visualization of the metadata of the collection. More recently, studies defined the requirements for more “transparent” digital archives, meant as tools facilitating content exploration even under imperfect conditions posed by digitized historical publications (Düring, Bunout, and Guido 2024), and started to investigate the use of graph-based narratives to analyze the interplay between the linearity of historical discourses and the non-linearity of the cultural heritage data (Günther et al. 2023). Through the development of the Mini-Muse research project, we merged current research coming from both the computer science and information design domains to identify novel and effective ways to access and analyse digitized publications for historical purposes. In particular, we implemented a user-centred design methodology to acquire preliminary knowledge on the integration of Natural Language Processing (NLP) algorithms and data visualization methods to enable researchers and students of history to investigate historical figures and their actions within their historical context.
Research methodology
Our research adopts a user-centred design approach, involving a pool of historians, to ensure that user interface features meet their needs. It consists of three main phases: user research, design and implementation of a basic working prototype and user test. The user research aims to gather the needs of users of cultural digital archives regarding the information and its visual representation. During this phase, we conducted semi-structured interviews with a group of 14 heavy users of cultural digital archives. The design and implementation of a basic working prototype aim to test the feasibility of users’ desiderata. During this phase, we implemented a set of NLP algorithms to automatically extract information from a corpus of issues of a digitized publication about history. More specifically, we focused on a set of articles from the Swiss Historical Journal. The journal has been published quarterly by the Swiss History Society since 1951 and made available online by E-Periodica, a service by ETH Library. Finally, the evaluation of the working prototype aims to gather feedback regarding ease of use, clarity and usability of the interface features we implemented. During this phase, we presented the prototype to the pool of historians involved in the user research and we gathered their feedback about the user interface through a set of online interviews and an anonymous survey.
User research: interviews with a pool of experts
The user research started with the selection of a group of 14 heavy users of cultural digital archives, including 8 historians and 6 other experts (librarians, archivists and developers of cultural digital archives). They are affiliated with universities and cultural institutions based in the three main language regions of Switzerland (German, Italian and French). The experts’ interests include politics, economics, technology, diplomacy, and science history. The experts were interviewed in one-to-one sessions to gather information on their research routines, their pain points in accessing and analysing historical content through cultural digital archives and their needs in terms of user interface features.
Design and implementation of a basic working prototype
The basic working prototype is an online user interface displaying content from the Swiss Historical Journal in a novel way. Its information system consists of a backend that stores data extracted from the publication and a frontend that displays it through a set of two views. The backend and frontend share data through the use of custom APIs we built (see Figure 1).
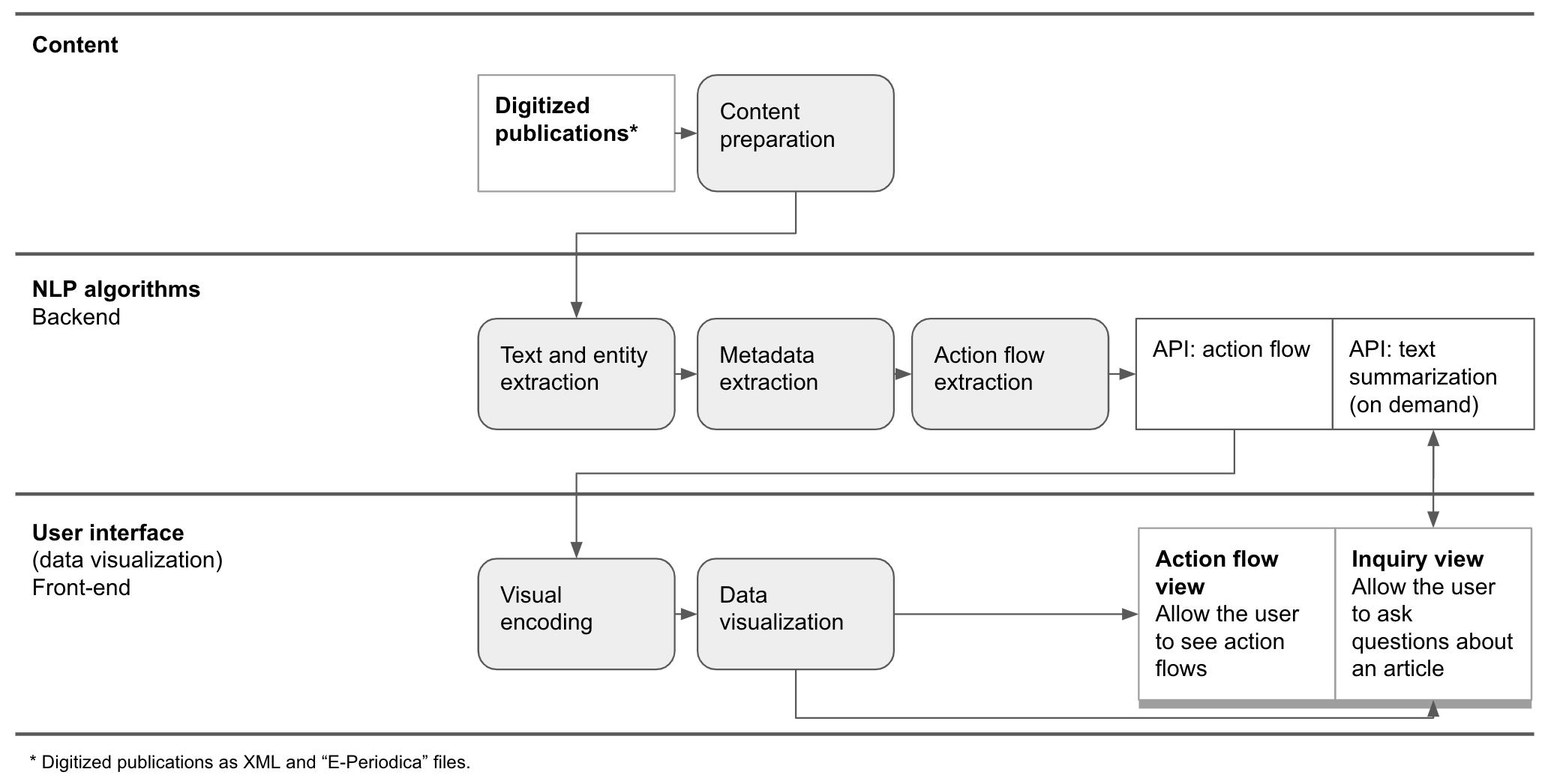
The working prototype is based on a selection of 25 recent articles. We selected the articles with the following attributes: focusing on politics (because several experts we interviewed were interested in this topic), in German and with historical figures shared among two or more articles. ETH Library provided us with the whole set of issues of the Swiss Historical Journal that are available via the E-Periodica digital archive both as text files, which were the output of OCR software applied to the digitized magazines and as an XML file containing the metadata of the whole issues of the journal. Then, we converted the content of the selected articles into a format suitable for the NLP algorithms, namely BioC JSON.
According to the experts’ desiderata, we gather both intrinsic and extrinsic content. As extrinsic content, namely the information that contextualizes the article, we gathered the title, author, publication date, the issue and the page number. As intrinsic content, namely the information that is contained within the article text, we gathered the historical figures (persons, institutions, and locations), and the actions they performed, with related dates and locations. The extrinsic content was extracted from the XML file provided by ETH-Library. The intrinsic content was extracted automatically through the implementation of an assembly of NLP algorithms consisting of two main parts: rule-based algorithms and LLM-based algorithms. The rule-based algorithms, including text Parsing, NER, Dependency Parsing, and Rule-Based Systems, extracted the set of intrinsic elements for each sentence of each article: historical figure, action, object, details, time, and location. The LLM-based algorithms, leveraging models like GPT-4 (gpt-4-0125-preview), use structured prompting and large text inputs to understand and interpret complex contexts, identify actions, actors, and relationships, and infer details like time and location for accurate action flow detection.
The frontend of the tool consists of two different views on the same set of articles: the action flow view and the article inquiry view. The action flow view allows the user to see the action flows, namely all the actions a historical figure undertook, with related locations and years, through the use of an interactive timeline. In this view, the user can filter the action flows according to the type of historical figure and sort them according to a list of parameters, including the number of actions per figure and the completeness of the actions’ metadata. The article inquiry view allows the user to ask questions about an article through the use of a chatbot connected to a custom LLM-based algorithm. This view lists the whole set of analyzed articles with their related action flows, lists of historical figures and locations, and an automatically generated short summary.
Test of the prototype
The test of the working prototype consists of a set of online meetings with the experts that we involved in the user research, to show them the set of prototype features, and an anonymous survey. During the online meetings, we gather the very first impressions about the working prototype in terms of usability and usefulness in regards to the historians’ main research tasks. Through the anonymous survey, which remains available online for two weeks, we gather more in-depth feedback on the usefulness of the features we introduced and suggestions for further studies on how NLP algorithm and data visualization can improve historical research.
Results and future works
The Mini-Muse project allowed us to gather an overall understanding of which are the possible research directions regarding the implementation of AI-assisted search tools for digitized publication archives. Through this research, we have found evidence of the fact that the AI extraction of action flows, and related graphical visualization, can have a great impact on historical research activities in terms of both speeding up and enhancing the quality of the work. The action flow allows historians to easily find correlations among historical figures and relevant documents mentioning them, and so fostering the comparison of different authors’ perspectives on the same event/figure. We have also gathered evidence that the action flow, combined with a chatbot that allows users to ask questions about a selected article, can lead to a shift in the search results paradigm within cultural digital archives. Instead of displaying document-centered results, where each item returned by the system is a whole document, the search results become content-centered. In this new approach, each item returned is the specific information requested, presented in both textual and visual form, along with its contextual background. This shift focuses more on historical figures or content, rather than on entire documents. Throughout this preliminary project, we encountered some constraints, including the current size of the prompt of LLMs algorithms, which is not enough for passing very long documents, and the low quality of the summaries generated by the algorithms, which are requested to be as accurate as possible by historians. In future works, we plan to investigate how to scale our NLP algorithms and data visualization models for larger collections of digitized publications and how to integrate other historical entities, such as the thematic area (i.e.: resistance, counter-reform, colonialism) for more advanced historical research.
References
Reuse
Citation
@misc{profeta2024,
author = {Profeta, Giovanni and Rinaldi, Fabio and Cornelius, Joseph
and Wanger, Regina},
editor = {Baudry, Jérôme and Burkart, Lucas and Joyeux-Prunel,
Béatrice and Kurmann, Eliane and Mähr, Moritz and Natale, Enrico and
Sibille, Christiane and Twente, Moritz},
title = {AI-Assisted {Search} for {Digitized} {Publication}
{Archives}},
date = {2024-09-12},
url = {https://digihistch24.github.io/book-of-abstracts/submissions/471/},
doi = {10.5281/zenodo.13908208},
langid = {en},
abstract = {Historians typically navigate digital archives to find key
figures (people, institutions, etc.) and understand the impact of
their actions on history. However, cultural digital archives,
relying on keyword-based search methods, often can yield numerous
but imprecise results about key figures across various sources. This
makes it difficult for historians to comprehend the chronological
and contextual facts around a historical figure. Mini-Muse is a
preliminary research project aimed at identifying data visualization
models and user interface features that help researchers and
students of history explore historical figures and their actions in
context. The project leverages Natural Language Processing (NLP)
algorithms and data visualization techniques. NLP algorithms extract
metadata from unstructured text and generate structured data about
key figures. Data visualization techniques further assist by
enabling visual analysis of each figure’s timeline and its
relationships. The project adopts a user-centred design approach to
ensure that the AI-assisted search system meets the needs of
historians. Preliminary analysis of the gathered results suggests
that the introduction of an "action flow view”, a user interface
that provides interactive timelines displaying historical figure’s
actions, holds great promise.}
}