Impresso 2: Connecting Historical Digitised Newspapers and Radio. A Challenge at the Crossroads of History, User Interfaces and Natural Language Processing.

The Impresso project pioneers the exploration of historical media content across temporal, linguistic, and geographical boundaries. In its initial phase (2017-2020), the project developed a scalable infrastructure for Swiss and Luxembourgish newspapers, featuring a powerful search interface. The second phase, beginning in 2023, expands the focus to connect media archives across languages and modalities, creating a Western European corpus of newspaper and broadcast collections for transnational research on historical media. In this presentation, we introduce Impresso 2 and discuss some of the specific challenges to connecting newspaper and radio.
digitised historical newspaper and radio, natural language processing, historical document processing, media history, digital history, historical scholarship
Introduction
The Impresso project pioneers the exploration of historical media content across temporal, linguistic, and geographical boundaries. In its initial phase (2017-2020), the project developed a scalable infrastructure for Swiss and Luxembourgish newspapers, featuring a powerful search interface. The second phase, beginning in 2023, expands the focus to connect media archives across languages and modalities, creating a Western European corpus of newspaper and broadcast collections for transnational research on historical media.
We introduce Impresso 2 and review the evolution from the first to the second project. We also discuss the specific challenges to connecting newspaper and radio, our efforts to adapt text mining and exploration tools to the affordances of historical material derived from different modalities, and our approach to conducting comparative and data-driven historical research using semantically enriched sources, accessible through both graphical and API-based interfaces.
Media Monitoring of the Past: The Impresso Projects
At the intersection of natural language processing, history and design, the Impresso projects focus on the processing, enrichment and exploration of large-scale historical media sources, with the aim of transforming the accessibility and usability of media archives for historical research.
The objectives of the first project (2017-2020) were to improve text mining tools for historical texts, to enrich historical newspapers with new information layers in the form of semantic annotations, and to integrate such data into historical research workflows by means of a newly developed user interface. Impresso 1 compiled and semantically enriched a corpus of digitised Swiss and Luxembourg newspapers, and designed a scalable infrastructure and user interface, that together form the Impresso app (Düring et al. 2024; Ehrmann 2021; Ehrmann et al. 2020; Romanello et al. 2020). Beyond simple browsing and often unsatisfactory keyword searches, this interface exploits new opportunities offered by semantic enrichments such as word embeddings, named entities, topic modelling and text reuse for content search and discovery, as well as comparative and critical perspectives on the available data (Düring et al. 2021, 2023, 2024). Its creation has been guided by the principles of co-design (where all team members actively contribute through continuous push-pull interaction), generosity (offering multiple complementary access points to the collection) and transparency (providing information on e.g. tools, document processing, and data quality). Impresso 1 aimed to harness machine reading to support historical scholarship, and its interface has helped popularise the use of text mining-based enrichment for the retrieval and exploration of newspaper articles - now a de facto standard.
Two key observations form the basis of the second Impresso project (2023-2027). First, although newspaper digitisation and online accessibility has outpaced that of broadcast archives over the past two decades, the digitisation of radio collections has recently caught up, making it easier for scholars to select them as sources and opening up new processing opportunities. Second, despite considerable progress in facilitating exploration of digitised sources, particularly for newspapers, existing digital portals still fall short of meeting the needs of historical research. This deficit arises for two main reasons. First, current frameworks for exploring digitised media archives remain fragmented, confined to digital archive silos with country-based institutional portals, and digital media silos, where enrichments and exploration capabilities are typically limited to one language, one modality and one media type. Even with enhanced search capabilities, the search horizon remains narrow. Second, portals offer only passive exploration of static collections, whereas historical research proceeds through iterative processes of association and comparison of multiple objects of study. Furthermore, as the digital transformation increasingly permeates all phases of historical research, historians are calling for new methods to critically analyse data, tools and interfaces.
Building on the achievements of Impresso 1, Impresso 2 envisions a comprehensive connection between media archives, aiming to enable the first-ever joint exploration of historical newspaper and radio content across temporal, linguistic, and national boundaries1. The aim is not merely to juxtapose collections and provide full-text search across them, but to enrich and connect these sources through multiple layers of semantic enrichment represented in a shared multilingual vector space, and to design appropriate, meaningful and transparent exploration capabilities for historical research from a transmedia and transnational perspective. These efforts are guided by original research on historical media ecosystems making use of this newly available data and of data-driven research methods.
To achieve this goal, Impresso 2 collaborates with 21 European partners, including national libraries, archives, newspapers, cultural heritage institutions, and international research networks.
Challenges in Enriching and Integrating Historical Digitised Newspaper and Radio Archives
As the mass media of their time, historical newspapers and radio broadcasts offer a daily account of the past and are key to the study of historical media ecosystems. Since the 19th century in print and the 1920s on air, these media have disseminated news, opinion, and entertainment, reported on events, and offered insights into the daily lives of past societies.
They have both shaped and been shaped by their social, cultural, and political environments. Until now, these sources have mostly been studied in isolation, resulting in a plethora of parallel national histories (Fickers 2018). Although there has been a ‘transnational turn’ toward broader geographical and temporal perspectives (Badenoch et al. 2013; Fickers and Johnson 2012; Cronqvist and Hilgert 2017), in media history, transnational and transmedia perspectives are rare, particularly when focusing on the distribution of content rather than institutional histories.
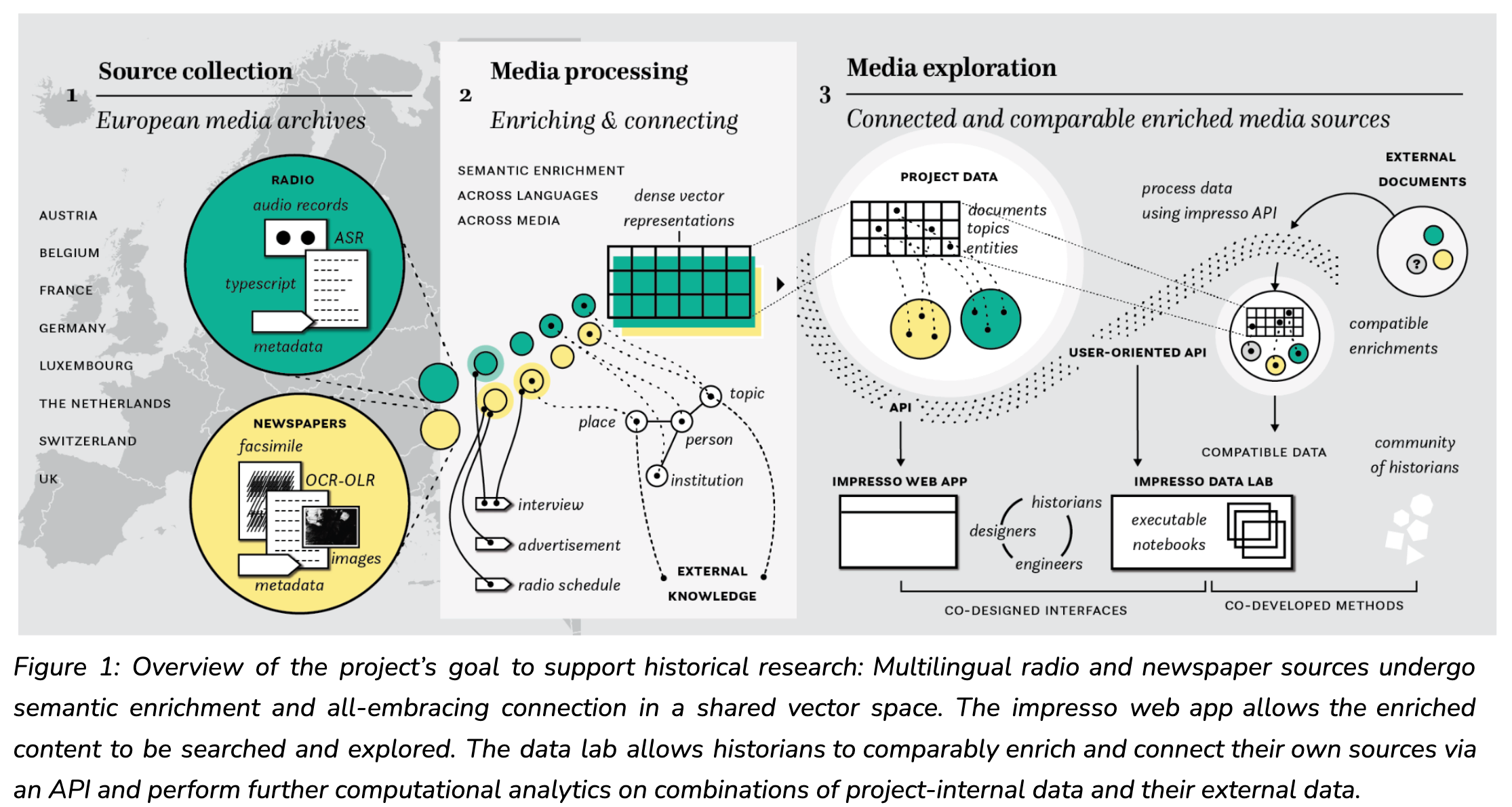
How can we accurately connect large collections of newspapers and radio, provide effective means for their exploration in historical research, and put content-based transmedia history into practice? Impresso 2 undertakes a multi-dimensional approach to integrating historical newspaper and broadcasts, focusing on four interconnected areas (see also Figure 1):
- Laying the foundation stone by compiling and making available an unprecedented corpus of Western European digitised print and broadcast media.
- Enriching and connecting historical sources by transforming noisy and heterogeneous sources into semantically enriched and structured data, ultimately connected in a common vector space.
- Conducting original historical research, which advances understanding of historical media ecosystems through various case studies, while also defining methods for data-driven analysis and identifying diverse user needs for data and interface design.
- Designing and implementing new interfaces by creating different entry points to the data and its enrichments.
In pursuing these objectives, Impresso 2 faces a set of unique challenges arising from the central issue of aligning and connecting newspaper and radio archives.

In many ways familiar sources, digitised radio and newspapers have however never been aligned and connected before. How to proceed? Their integration requires a careful examination of the nature of these media objects, their preservation by cultural heritage institutions, specific characteristics as archival records and legal boundaries which determine access to them. While many questions remain unanswered at this stage, we provide a brief overview of each project focus area, primarily focusing on the key issues raised by integrating radio and newspapers: how to document and contextualise the corpus, how to align radio and newspaper historical documents, how to integrate their content cross-lingually, how to analyse and compare, and how to explore and interact with the data2.
The Impresso Corpus: A Silo-Breaking, Transmedia and Transnational Corpus
The foundation of Impresso 2 is the creation of a large corpus of print and broadcast media collections across several countries. Building on the newspapers collected in the first Impresso project, the corpus expands to a geographically and historically coherent set of neighbouring countries, encompassing both newspaper and radio archives from each. To begin, let us review the core characteristics of the two media sources. Newspapers were disseminated and are preserved in print, while radio broadcasts, originally transmitted as audio signals, are preserved through audio recordings or typescripts (the text read by the speaker). Newspapers were typically published daily, with one issue per day, whereas radio broadcasts followed a highly variable rhythm, documented in radio schedules available in dedicated magazines, unpublished internal listings, and newspapers (see Figure 2). From a digitised archive perspective, newspaper materials consist of facsimiles and their transcriptions obtained via optical character recognition (OCR), whereas radio materials include facsimiles and OCR for typescripts and radio schedules, and audio recordings and transcripts generated through automatic speech recognition ASR for broadcasts. These materials encompass different modalities, such as text and image for newspapers, and text and sound for radio.
Data Acquisition and Sharing Framework
Acquiring such a large and diverse corpus is a lengthy and complex endeavour with several obstacles: collections include various data elements (metadata, facsimiles, audio records, transcripts) with differing copyright statuses and are held by institutions across multiple countries, each with its own jurisdiction and legal constraints based on data owners’ preferences and institutional policies. We aim to make these sources accessible to researchers for operations such viewing, searching, and exporting. To address these issues, we have developed a dual approach: operational, by implementing a rigorous organisation to conduct dialogue and facilitate data exchange with our partners; and legal, by designing a modular data sharing and access framework that respects copyright and institutional constraints while maximising research opportunities through differentiated access. We believe that this operational and legal basis will help to break down institutional barriers.
Rich Contextual Information for Historical Research
The practical acquisition of the corpus also provides an opportunity to deepen our understanding of the sources, which is essential for their use. Although radio and newspaper archival records come with standard metadata, this information is often heterogeneous and varies significantly in content, quantity and quality across collections and institutions. Additionally, there are other sources of contextual knowledge, including unspoken or unwritten information. Two ongoing initiatives aim to further document the production and preservation of these archives to provide rich contextual information for historical research, all the more important in this multi-source context.
The first seeks to leverage the information contained in newspaper directories, following the approach outlined in (Beelen et al. 2022). As a starting point for the Swiss context, we are focusing on extracting semi-structured information from the Swiss Press Bibliography published by Fritz Blaser in 1956 (Blaser 1956). This bibliography documents in great detail about 480 newspapers and around 1,000 periodicals published in Switzerland between 1803 and 1958. It offers rich insights into the origins and history of Swiss newspapers, which can be used to enhance the documentation of newspapers in the Impresso corpus and interface, as well as support the study of the newspaper ecosystem in Switzerland. A similar approach will be used to trace the development of radio programmes through radio schedules and magazines.
The second initiative focuses on radio, adopting an oral history perspective to gain a better understanding not only of radio archives, but also of each archive custodian. What important aspects about these archives might we be unaware of? The ‘Oral History of Radio Archivists” (OHRA) addresses this by conducting semi-structured interviews of Impresso audio partners.These interviews explore topics such as archival preservation and documentation policies, digitisation priorities, and the evolution of data quality over time, with the aim of providing complementary narrative descriptions of radio archives.
Enriching and Connecting Historical Media Collections
A critical step towards Impresso’s vision is the application of text and image processing techniques to the corpus. We aim to enrich and connect media sources through multiple layers of semantic enrichment, ultimately represented and connected in a common vector space. This endeavour involves three main steps; we discuss here only the first and the last.
Source consolidation. Sources come in various digital formats and exhibit varying levels of refinement, both in terms of OCR and ASR quality and in the granularity of document layout analysis and article segmentation. We harmonise historical document data by establishing a consistent data representation and ensuring uniform characterisation of the material across all collections.
First, we aim to define an appropriate and consistent data representation framework for both radio and newspaper digital materials. By ‘representation’, we refer to how data or information is effectively encoded and structured in a machine-readable format. The world of digitised newspapers is well understood, with a clear and consistent structure: a title consists of issues, which include pages containing articles and images. Each issue’s content is organised into sections, a framework that intersects with journalistic genres, exhibits distinct characteristics in both layout and content, and evolves over time. In contrast, digitised radio broadcasts present a more complex and heterogeneous landscape, lacking a shared definition of what constitutes a ‘standard’ broadcasting unit. There are varying levels of content organisation and an uneven distribution of material over time. Drawing from concrete evidence from files on disk, we carefully inventory all source elements for both media types, refining the terminology for newspapers and radio components – an often challenging process. With this groundwork, we then explore how to align collections’ structure and compositional units of both media sources. This alignment design, developed in parallel with data acquisition and in collaboration with archive partners, also informs and influences the rendering of sources in the interface.
Second, we elevate the corpus to a consistent and higher-quality level, through the assessment and optimisation of OCR and ASR quality, along with the homogenisation of content item segmentation and classes. The objective in this regard is to create “bridges” between radio broadcast and newspaper content types, enabling the retrieval of specific categories–such as editorials, sports-related (sub)sections, or radio schedules–across a set of titles, languages and a specific period in all digitised material.
Cross-lingual connection of sources. After enriching historical sources with semantic information to facilitate content-related search facets and support the exploration and comparison of people, locations, keyphrases, topics, and semantic classes across time periods, languages, and media channels (the second step not discussed here), a crucial task is establishing meaningful connections at the content level across both media, both mono- and cross-lingually. This process shifts focus away from structure, concentrating instead on content and its enrichments, with the goal of computing effective vector representations. This is relatively easy to achieve on a monolingual basis, but becomes more challenging cross-lingually, where the goal is to compute meaningful similarities of multilingual representations across languages.
Unlocking the Dynamics of Historical Media Ecosystems
The focus of historical research activities within Impresso 2 is on examining influence—encompassing actors, themes, and formats—within a transnational media ecosystem. In our context, influence refers to the ability of individuals, groups, organisations or even texts (e.g. books, articles) to shape, direct, or alter narratives, imagery, content, opinions, behaviours, or outcomes related to a particular subject, issue, or topic represented by and through the media. Several case studies, which are both conceptually and methodologically complementary, investigate influences from various perspectives: external to the media, within the media ecosystem, within individual institutions, and across different content formats. This transnational and transmedia research aims to revisit and compare media autonomy, examining interactions between different media forms, such as radio and newspapers, beyond their competitive aspects. A central challenge is extend the historian’s traditional skill of making meaningful comparisons from incomplete and diverse sources to a large-scale, multilingual and transmedia corpus interconnected and enriched with semantic annotations. To this end, we are developing a comparative framework that leverages our data, tools, and interfaces.
Interfaces
To facilitate research on our data, we are developing two complementary research-oriented user interfaces: the Impresso web app, a powerful graphical user interface, and the Impresso data lab, built around a user-oriented API. While the search interface offers a more traditional entry point to explore sources, enable close reading and the compilation of research datasets, the data lab is designed for automating access and enabling computational analysis. Our efforts focus on providing an easy programmatic access to the corpus and its enrichments through a public API and the Impresso Python library, allowing users to annotate external documents with Impresso tools and import external annotations into the web app (annotation and import services), and ensuring transparency with comprehensive documentation, including datasets, models notebook galleries, and tutorials. To further inform the design of the Impresso Datalab, we are surveying current approaches and realisation around data labs for computational humanities research (Beelen et al. 2024).
References
Footnotes
Impresso is the result of the collaboration of an interdisciplinary team composed of computational linguists, designers and historians. In addition to the presenters, the team includes: Marten Düring (co-PI, UniLu), Simon Clematide (co-PI, UZH), Ferdaous Affan (UniLu), Emanuela Boros (EPFL), Kaspar Beelen (London University), Estelle Bunout (UniLu), Pauline Conti (EPFL), Daniele Guido (Luxembourg University), Andrianos Michail (UZH), Arthur Michelet (UNIL), Juri Opitz (UZH). More on the team here.↩︎
It should be noted that the project has only recently started and all areas of work are in progress.↩︎
Reuse
Citation
@misc{ehrmann2024,
author = {Ehrmann, Maud and Ruppen Coutaz, Raphaëlle and Clematide,
Simon and Düring, Marten},
editor = {Baudry, Jérôme and Burkart, Lucas and Joyeux-Prunel,
Béatrice and Kurmann, Eliane and Mähr, Moritz and Natale, Enrico and
Sibille, Christiane and Twente, Moritz},
title = {Impresso 2: {Connecting} {Historical} {Digitised}
{Newspapers} and {Radio.} {A} {Challenge} at the {Crossroads} of
{History,} {User} {Interfaces} and {Natural} {Language}
{Processing.}},
date = {2024-09-12},
url = {https://digihistch24.github.io/submissions/443/},
doi = {10.5281/zenodo.13907298},
langid = {en},
abstract = {The Impresso project pioneers the exploration of
historical media content across temporal, linguistic, and
geographical boundaries. In its initial phase (2017-2020), the
project developed a scalable infrastructure for Swiss and
Luxembourgish newspapers, featuring a powerful search interface. The
second phase, beginning in 2023, expands the focus to connect media
archives across languages and modalities, creating a Western
European corpus of newspaper and broadcast collections for
transnational research on historical media. In this presentation, we
introduce Impresso 2 and discuss some of the specific challenges to
connecting newspaper and radio.}
}