A Digital History of Internationalization. Operationalizing Concepts and Exploring Millions of Patent Documents

Our presentation reflects on the experience gained in an ongoing SNSF-funded research project investigating the internationalization of patent systems. In our research, we mix different methods: traditional historical methods allow us to shed light on the role of intergovernmental agreements and of private networks of patent specialists; digital analysis enables us to trace how internationalization stemmed from patent practice itself, and to study the activity of patentees that have left few historical traces. Relying on a large corpus (over 4 million documents) of digitized patents, we use text mining and computer vision techniques to explore the corpus and operationalize the concept of internationalization. In this paper, we focus on the challenges of matching (almost) identical drawings between patents of different countries, combining image embeddings (obtained by using a pretrained convolutional neural network) and feature matching (SIFT).
patent data, computer vision, operationalization, digital exploration
Introduction
Our presentation reflects on the experience gained in the ongoing SNSF-funded research project The Internationalization of Patent Systems: From Patent Cultures to Global Intellectual Property. As recent debates on price of, and access to, patented COVID-19 vaccines have recalled, intellectual property rights are of great importance on a global scale. Our research investigates how patents have become, albeit incompletely, such globally relevant rights. While this internationalization is often seen as the consequence of agreements between macro-actors such as states, this project argues that this internationalization stems equally, if not more, from the networks of actors, economic strategies, texts and images involved in patent practices. To explore these, our project relies on the digital analysis of a large corpus of digitized patent documents, using text mining and computer vision techniques.
Opportunities of Digital Analysis for a History of Patent Internationalization
Our research project combines traditional historical methods with digital analysis. These various methods are more or less relevant depending on how the “internationalization” of patents is understood. The adoption of a legal agreement (the Paris Convention of 1883) by various states made patents internationally more relevant: because of the emergence of diplomatic discussions in matters of intellectual property, and because it made it easier for corporations to obtain rights for the same technology in different countries simultaneously. Similarly and relatedly, from the late 19th century on, patent specialists gathered in international private networks and advocacy groups. Both of these aspects can be studied through close-reading of archival materials and printed sources.
Digital methods enable us to go further and examine a third meaning or aspect of internationalization: border-crossing patent practice and related business strategies. Indeed, patenting abroad was not exclusively the activity of multinational companies, nor of their founders and chief engineers, but also of craftsmen and low-level employees. Unlike, say, Thomas Edison or Alexander Graham Bell (see e.g. Beauchamp 2015), these patentees have left few traces outside of the patent record and even fewer, if any, that could shed light on their motivations and strategies. The large-scale digitization of patent documents thus creates the opportunity to study the activity of a wider variety of patentees.
Furthermore, digital methods allow us to quantitatively study broad changes in patenting practices. For instance, over the period under consideration, a growing proportion of patents were granted or assigned to corporations, rather than individual inventors (Lamoreaux et al. 2009; Veyrassat 2001; Fisk 2009, chap. 6). How did this reflect on international patenting? More generally, what proportion of patents was granted, in different countries and at different times, to (foreign) companies and individuals holding similar patents in other countries? How did the situation vary from industry to industry?
Available Digitized Sources
Because patents constitute a legal claim of exclusivity, a detailed description of the invention is required by the law, inter alia to allow courts to assess whether competing technical devices or processes constitute illegal imitations. From the second half of the nineteenth century onward, most countries systematically published these descriptions, so-called patent specifications. We rely on a large corpus of these documents that have been digitized by patent offices for their own current activity (especially for assessing the novelty of patent applications).
Our dataset currently includes around 4 million patent specifications from four large industrial countries: France, Germany, the United Kingdom and the United States. These countries represent major players in the discussions around the Paris Convention. Their residents also account for a large proportion of patents taken abroad. Furthermore, it has been proposed that they constitute distinct “patent cultures” that have constituted models for other countries (Gooday and Wilf 2020). This corpus however reproduces the historiographical tendency to neglect smaller and less-studied countries. To account for this, we plan to include patent specifications from additional states at a later point.
The main source of our data is the European Patent Office (EPO). Digitized specifications were downloaded by using Open Patent Services, an API offered by the EPO. We have also downloaded metadata through the same channel, including information such as a title for the patent; the date the patent was applied for; the date it was published; the name and country of the inventor and/or applicant; so-called “family data”, linking this specification to other ones. However, coverage is very uneven. For instance, we have no metadata for most German specifications before 1914.
Operationalizing and Exploring Internationalization
To quantitatively trace the internationalization of patent practice, we must define this concept more precisely, or rather stipulate how we are going to measure it: we must “operationalize” the concept, i.e. turn it into “a series of operations”, “building a bridge from concepts to measurement, and then to the world” (Moretti 2013, 104). Deciding on a series of operations happens in interaction with a process of close examination and exploration of the dataset.
Speaking of a network of text and images implies that we can link patents from one country to those granted in another. The available “family” metadata already does so, but using it as an entry point for exploration shows that we would severely underestimate the extent of international patenting by relying only on that indication. However, this exploration reveals how very similar patents can be, confirming our expectations. We can match specifications by comparing patentee names and titles. Because available metadata is incomplete, these elements also need to be extracted from the patent document itself through text mining.
Exploration leads to a further possible operation: matching the drawings printed in these documents. Unlike the text, which changes between countries because it is translated and sometimes adapted to local patent practices and regulations, the drawings have often been reused (almost) identically from one country to another (Figure 1).
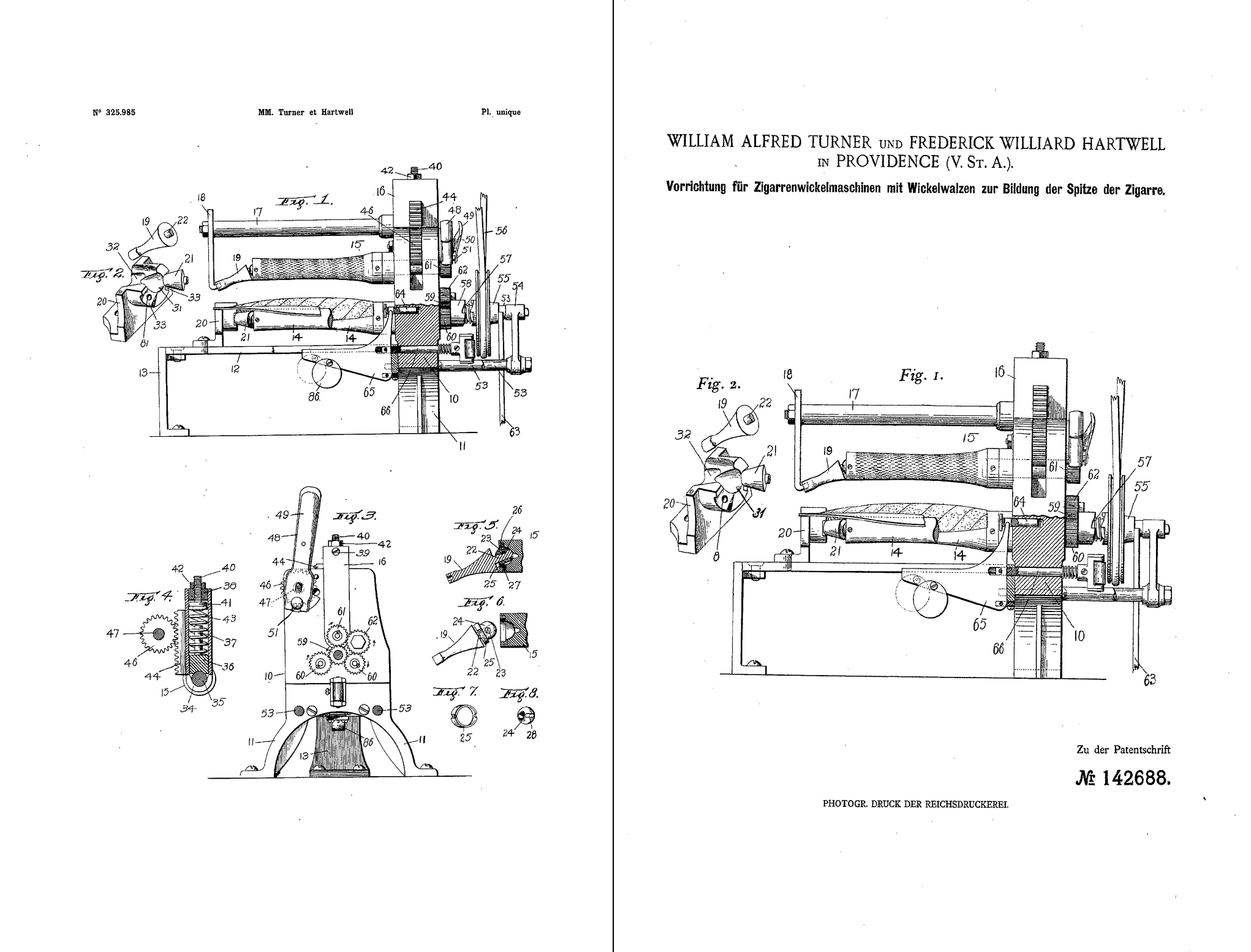
Implementing Image Matching
In recent years, computational exploration and analysis of images have attracted a growing interest in digital history (Arnold and Tilton 2019, 2023; Wevers and Smits 2020). Among other approaches, historians have used convolutional neural networks (CNNs) to generate numerical representations of images, so-called image embeddings, and then find similar pictures. Pre-trained CNNs have been shown to be useful on historical documents even though they were built for another purpose, typically classifying colored photographs in categories such as iPod and hair_spray, as in the ImageNet training data.
However, in itself, this method proved insufficient for our needs. First, the available images are digitizations of whole pages in the specifications. These pages might not be found to be similar, because of changes in the arrangement of the drawings on the page or because of differences in overall layout (see again Figure 1). To address this first limitation, we segment the pages by identifying regions of contiguous black pixels. A second limitation of using image embeddings for our purpose is that we are not looking for general similarity, e.g. in the overall shape of the figures, but for (near) identity. This distinction could not be made based on similarity measures given by the embeddings, possibly because of how the models were trained.
Another family of computer vision algorithms, feature detection and matching, is more appropriate for our goal. Predating the breakthrough of CNNs by a decade, Scale-Invariant Feature Transform (SIFT) remains one of the best available methods (Lowe 2004). SIFT can for instance find a photographed object in another photograph, even if it is scaled or rotated. However, SIFT is computationally intensive, which presents us with a challenge because of the amount of data we process. While faster algorithms exist, they have so far given inferior results on our data, leading especially to many false positives.
Best results were obtained by combining a CNN and SIFT. Image embeddings and an efficient indexing algorithm (Hnswlib - Fast Approximate Nearest Neighbor Search 2024; Malkov and Yashunin 2018) allow us to reduce the search space: instead of using SIFT to compare a segment from a French patent to all the segments of British, German and US patents, we only compare it to the segments with the most similar embeddings. Preliminary results of using this method on French and German patents issued around 1902 indicate a very high precision, with very few false positives (recall still needs to be evaluated).
Back to Exploration and Future Work
Our early results prompt further exploration, leading to new insights. For instance, some of the matches point to metadata errors, e.g. wrong country indications in French patents. It also leads us to question some of our assumptions. Assuming that a patent in one country would have one corresponding patent in another, we used embeddings to get, for each segment in country A, the two segments most similar to it in country B. However, in our early results, one French patents matched six different German patents. This suggests that we might need to apply SIFT to compare each segment A to a greater number of similar B segments. Further future work includes combining matching the drawings and matching other data points. All in all, our use of computer vision methods, while not yet robust enough to answer our research questions, yields promising results demonstrating that the concept of internationalization can be operationalized in this way.
References
Reuse
Citation
@misc{baudry2024,
author = {Baudry, Jérôme and Chachereau, Nicolas},
editor = {Baudry, Jérôme and Burkart, Lucas and Joyeux-Prunel,
Béatrice and Kurmann, Eliane and Mähr, Moritz and Natale, Enrico and
Sibille, Christiane and Twente, Moritz},
title = {A {Digital} {History} of {Internationalization.}
{Operationalizing} {Concepts} and {Exploring} {Millions} of {Patent}
{Documents}},
date = {2024-09-12},
url = {https://digihistch24.github.io/submissions/482/},
doi = {10.5281/zenodo.14851527},
langid = {en},
abstract = {Our presentation reflects on the experience gained in an
ongoing SNSF-funded research project investigating the
internationalization of patent systems. In our research, we mix
different methods: traditional historical methods allow us to shed
light on the role of intergovernmental agreements and of private
networks of patent specialists; digital analysis enables us to trace
how internationalization stemmed from patent practice itself, and to
study the activity of patentees that have left few historical
traces. Relying on a large corpus (over 4 million documents) of
digitized patents, we use text mining and computer vision techniques
to explore the corpus and operationalize the concept of
internationalization. In this paper, we focus on the challenges of
matching (almost) identical drawings between patents of different
countries, combining image embeddings (obtained by using a
pretrained convolutional neural network) and feature matching
(SIFT).}
}