Efficacy of Chat GPT Correlations vs. Co-occurrence Networks in Deciphering Chinese History

Capitalism, Communism, ChatGPT
Introduction
In our 2021 paper, “Network of Words: A Co-Occurrence Analysis of Nation-Building Terms in the Writings of Liang Qichao and Chen Duxiu,” (Journal of Historical Network Research, 5:154-185), we created a word co-occurrence network to plot the relationship between selected words, in order to compare different interpretations of terms such as “democracy,” “constitutionalism,” and “citizen” in the writings of two famous Chinese intellectuals of early Republican China.
We now propose to re-examine the writings of Chen Duxiu (1879-1942), the co-founder of the Chinese Communist Party, by using the innovative Large Language Models (LLMs) LLMA and ChatGPT (Bian et al. 2021). We intend to leverage ChatGPT to detect changes in Chen’s thinking about the theory and practice of Marxism and Communism. Through embedding and prompt engineering, we plan to extract topic sentences, generate summary statements and estimate topic opinions on these summaries. Our work introduces two key innovations:
- the utilization of advanced AI methodologies grounded in extensive language models, as opposed to traditional statistical techniques that often relied on oversimplified assumptions, and
- an extension of our analysis to sentences rather than individual words, allowing for richer contextual understanding.
A brief biography of Chen Duxiu is as follows: As a young boy Chen chafed against the traditional preparation to study for the all-important civil service exam. He deplored the ineffectiveness of gaining governmental positions through rote memorization of ancient classics. Surprisingly he placed first in the entry level of this exam. Soon Chen left to study in Japan, where he first encountered Western democratic philosophies such as those of John Stuart Mills, Jean Jacques Rousseau and Montesquieu. He concluded that the only way to save China was to overthrow the dynasty. Returning to China in 1903 he joined an assassination squad and published newspapers rallying his countrymen to fight foreign imperialism and to overthrow the dynasty. One of his journals, called Xin Qingnian 新青年 [New Youth], whose contributors ultimately consisted of some of the most respected and celebrated scholars and intellectuals of the time, made Chen a celebrated public intellectual. Together these authors pushed through the national language reform, denounced the restrictive Confucian ethos, and advocated scientific thinking, democracy, and individual freedom.
With the disappointing outcome from the Treaty of Versailles in 1919, whereby China’s hope to recover German occupied Shandong peninsula was dashed, Chen and many of his colleagues became disillusioned with Western style democracy. Within two years, Chen co-founded the Chinese Communist Party (CCP) with the help of Russian Comintern agents and turned his attention to political activism. Politics proved to be treacherous, however, and Chen was scapegoated for the failure of Comintern policies in China and ousted from the CCP in 1929. He was jailed by Chiang Kai-shek, head of the Nationalist Party (GMD), from 1932-1937, and released from prison at the onset of the Resist Japan war. Distancing himself from both the CCP and the GMD, Chen became a political pariah whose writings few dared to publish. Undaunted, he continued to comment on the state of Chinese politics and died in penurious circumstances in 1942.
What were Chen’s final views on Western democracy, capitalism, and communism? In his youthful optimism, he declared France to have gifted humanity with three powerful concepts: human rights, evolutionary theory, and socialism (Duxiu, n.d.). Caught in the power struggle between Stalin and Trotsky, Chen lost his political leadership. Tragically he also lost two of his sons at the hands of the GMD. Did the vicissitudes of life affect his thinking? We turn to his essays to find out.
Methodology
The central objective is to compare the efficacy of our earlier co-occurrence network methodology with the novel ChatGPT approach. We seek the best method to detect Chen’s ideological evolution over time. We used the corpus of Chen’s writing, consisting of 892 articles and 1,347,699 characters (Duxiu 1914--1940).
Figure 1 represents the flow chart for our analysis.
Updated Comparative network analysis based on LLM embedding space
We selected thirty keywords and will use a network approach to explore the relationships among them, hypothesizing that changes in network topology will reflect shifts in ideology. To construct the network, we treat each keyword as a node. Then, we compute the similarity between these keywords, adding an edge between two nodes if their similarity is high. To measure similarity, we leverage a large language model (LLM), specifically Colossal-LLaMA-2-7b-base. First, we input an article and use the LLM to tokenize every word, generating embedding coordinates for each token. We then obtain the embeddings for each keyword, noting that the same keyword may yield different embeddings depending on the context. With these embeddings, we calculate cosine similarity to assess connections between keywords. Below is a diagram illustrating our pipeline.
- Question: As his life evolved, what was Chen’s final view on democracy?
- Approach 1: Building the Key Word Co-occurrent Network.
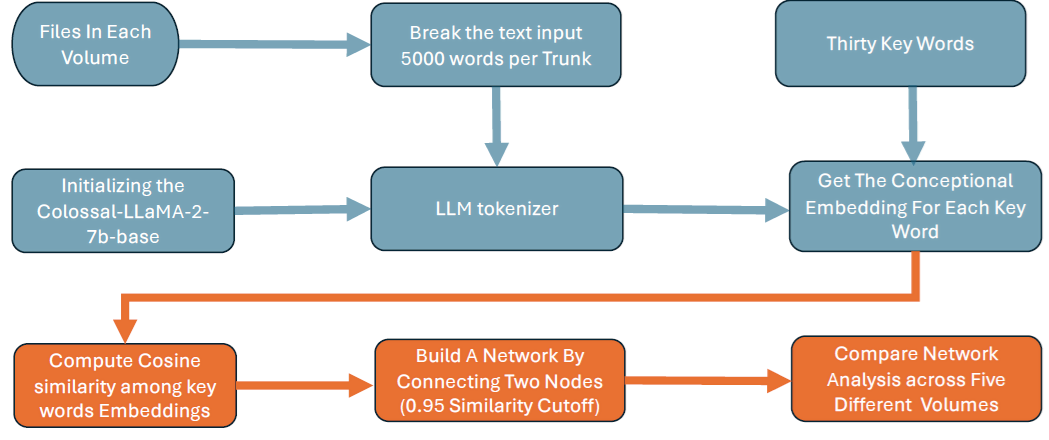
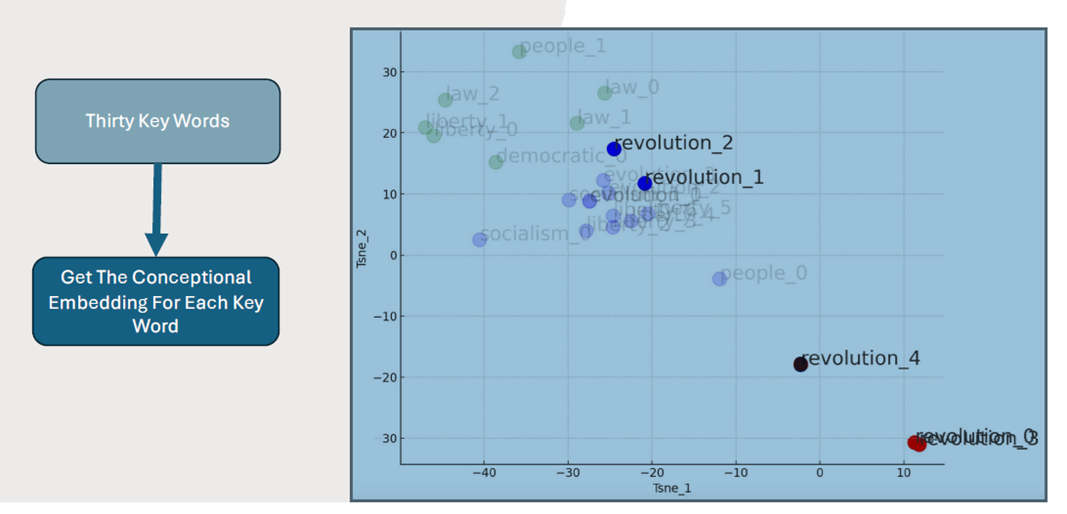
Figure 2 presents a context-dependent embedding visualization based on the t-SNE dimensionality reduction method. In the figure, the word “revolution” appears four times, with each location reflecting a unique context. When calculating cosine similarity between two keywords, this contextual multiplicity is taken into account: if the cosine similarity between any pair of keywords across different contexts exceeds a predefined threshold, an edge is created between those two keywords. We have a total of five volumes of articles, each used to construct a keyword network specific to its volume. By examining changes in network topology across these volumes, we can observe shifts in Chen’s ideology.

Comparative Analysis of Network Structure revealed Change in Chen’s Understanding of democracy from 1930s to 1940s.
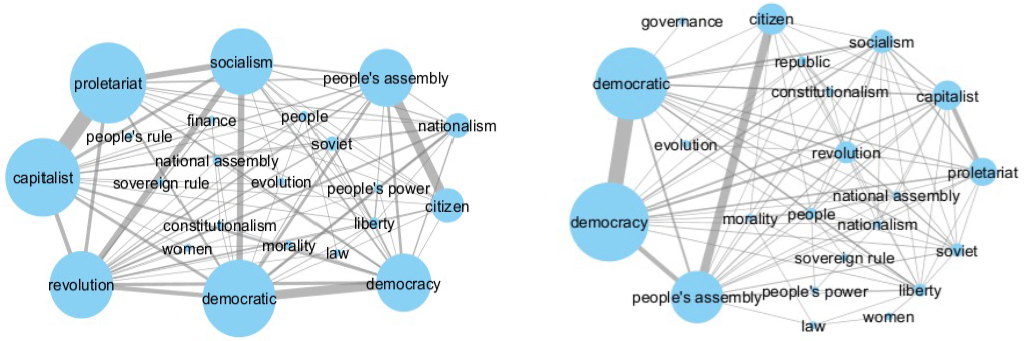
Text Summarization & Sentiment Analysis
In this step, we will apply two methods, one of which involves using the Colossal-LLaMA-2-7b-base model. From this collection we selected fifteen articles that were salient in his thoughts on political theory, written in the years 1914-1940 (Duxiu 1914--1940). The analysis was performed using various Python libraries and tools. Transformers were used for loading pre-trained language models, FAISS for efficient similarity search and clustering, Jieba for Chinese text tokenization, and Docx for handling Word documents. Numpy, Pandas, and Sklearn were used for numerical operations and data handling, and Langchain was used for managing document schemas and prompts.
Preprocessing and Text Tokenization
The Chinese text was tokenized using Jieba, which segmented the text into meaningful tokens. Sentence Detection: A custom function called “chinese_sentence_detector“ was implemented to detect sentences based on punctuation marks specific to Chinese (e.g., “。”, “!”, “?”).
Embedding and Similarity Analysis
We loaded the Colossal-LLaMA-2-7b-base model. Sentences from the documents were embedded using the loaded model. The embeddings were stored in a NumPy array. Next, we computed pair-wise cosine similarity scores between the embeddings of all sentences.
Query Processing
The question: “Is this article in favor of communism or capitalism?” [这篇文章是支持共产主义还是支持资本主义?”] was embedded using the same model and tokenizer. The FAISS index was used to search for the top 5 sentences most similar to the query. The indices and distances of the closest matches were retrieved.
Output Generation
The sentences retrieved from the similarity search provided the context for answering the query. The following steps illustrate the workflow for a specific set of documents:
- Define the volume pattern for document selection.
- Embed the sentences in the document using the pre-trained model.
- Construct the FAISS index for efficient search.
- Perform query embedding and similarity search.
- Retrieve and save the top similar sentences as the answer to the query.
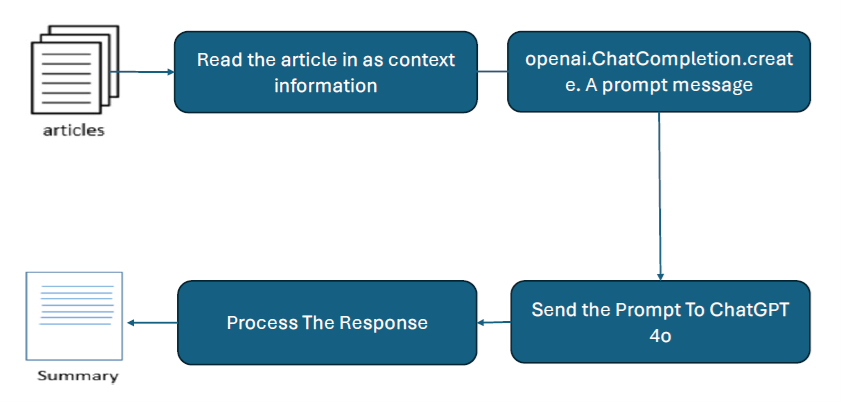
For the second part of the analysis, we employed a combination of natural language processing (NLP) techniques and the GPT-4 API to classify political opinions in textual documents. The primary objective was to determine whether the texts supported communism or capitalism. We used Python for automating the analysis process, integrating various tools and libraries to achieve this.
Question Design
We formulated a question to extract the political sentence from the text. The question posed to the GPT-4 model was: “Is this article in favor of communism or capitalism?” [这篇文章是支持共产主义还是支持资本主义?”]
API Request
The openai.ChatCompletion.create method was utilized to interact with the GPT-4 API. We constructed a prompt with the following messages:
- System Message: Provided context to the model, indicating that it was functioning as a helpful assistant.
- User Messages: Included the embedded document content, followed by instructions for providing a score on a scale from -2 to 2 (where 2 indicates strong support for communism and -2 indicates strong support for capitalism) and a detailed explanation within 200 to 300 words.
Response Extraction
The response from the API was parsed to extract the generated content, which included the classification score and explanatory text. In summary, our method leveraged the GPT-4 API to analyze and classify political opinions in text documents. By embedding the documents and querying the model with specific questions and instructions, we automated the classification process and systematically stored the results for subsequent review.
Results
The summaries of the fifteen articles produced by Llama were perfunctory and inconclusive. At times Llama changed the order of sentences in an effort to answer the query, but it often generated a text that was more a random collection of sentences than a cohesive answer to the question.
ChatGPT4 produced a much more systematic and accurate summary for each article. However, we detected five articles that variously missed the intent of the essay, or forced fit the answer, or gave a wrong numerical coding. Of the remaining ten articles, ChatGPT4 best answered the question: “Is this article in support communism or capitalism?” when the essay consistently argued for one point of view, such as in “Shehui zhuyi piping” [A critique of socialism] and “Makesi xueshuo” [A study of Marxism]. Where ChatGPT4 ran into problems is when the writing was nuanced and contained multiple points of view. Because of its effort to answer the question, it sometimes force fit the answer by implying connections that did not exist. We briefly describe these five issues below.
Missing the context and the main argument of the article
In his 1914 article, “Aiguo xin yu zijue xin” [Patriotism and self-awareness], Chen famously shocked his readers by concluding that a nation which did not care for its people should not expect support from its citizens, and that such a nation should be allowed to die. Lacking such context, ChatGPT4 picked up on Chen’s description of an ideal nation but did not underscore the novelty of his perspective. It coded the article as -1 (mildly in support of communism). The article never mentioned communism, and at the same time, the command was to rate articles from -2 to 2.
Trying too hard to answer the question
In the 1915 article, “Fa lanxi ren yu jinshi wenming” [The French and contemporary civilization], Chen praised socialism and mentioned French socialists such as Henri de Saint-Simon, Gracchus Babeuf and Charles Fourier. It concluded that Chen was in favor of socialism but not rejecting capitalism. It erroneously stated that socialism was the same as communism, which did not appear in the text.
Inaccurate coding
In the 1916 article, “Tan zhengzhi” [Talk about politics], Chen strongly attacked the bourgeois exploitation of the working class, which was accurately picked up by ChatGPT4. However, it gave the article a +1 code, meaning it was somewhat in favor of capitalism. This is surprising since it concluded that the article was in favor of communism. Similarly in the 1924 article, “Women de huita” [Our response], Chen was defending the reason why the CCP was part of the GMD (an ill-fated decision ordered by Stain), and strongly argued for class struggle between the bourgeoisie and the proletariat. ChatGPT4 recognized this interpretation but surprisingly rated the article as +1 (mildly in support of capitalism).
Missed by a wide margin
Historians often cited the conflicting tone of “Gei Xiliu de xin” [A letter to Xiliu], one of Chen’s last essays, as indicative of his ambivalence about communism. He railed against Stalin’s dictatorship, the lack of freedoms of speech, assembly, publishing, the right to strike, and the right to an opposition party in Russia. He wrote that in his opinion, bourgeois democracy and proletarian democracy are similar in nature but differed only as a matter of degrees (Duxiu 1940). Bourgeois democracy, Chen explained, was the culmination of a struggle by millions of people over six hundred years, and that gifted the world with the three big principles of science, democratic system and socialism. “We must recognize” he stated, “that the incomplete democracy of England, France and the United States deserve to be protected.” Chen created a table comparing the freedoms people enjoyed in a capitalist democracy versus those under Stalin and Hitler, and asked, “Would any Communist dare curse bourgeois democracy?” ChatGPT4 picked up the anti-fascist sentiment but missed Chen’s ambivalence toward bourgeois democracy. Instead it described the article as Chen’s way to use the struggle between fascist and Western democratic countries to advance the causes of the proletariat. We found this conclusion to be off the mark and as an attempt to force the conclusion.
Conclusion
ChatGPT 4 is able to detect strong and consistent sentiments in articles, but would force fit its answer and rationalize connections that did not exist. It does less well when multiple viewpoints are expressed, and it does not know the historical context. Llamas is unable to perform the analysis at all.
In conclusion, the use of ChatGPT 4 for analyzing historical texts presents both significant advantages and notable challenges. ChatGPT 4 has demonstrated its capability to detect strong and consistent sentiments in articles, providing systematic and accurate summaries in many cases. However, it occasionally forces connections that do not exist, particularly in texts with nuanced or multiple viewpoints. This limitation highlights the importance of historical context, which the model sometimes misses, leading to misinterpretations of the larger point. Conversely, the Llama 2-7b model was unable to perform the analysis adequately, emphasizing there may be a need for larger models. Our study underscores the need for continuous refinement in leveraging AI methodologies for historical text analysis. Future work should focus on enhancing the model’s contextual understanding and its ability to handle complex, multi-faceted arguments, thereby improving its overall efficacy in historical and ideological analysis.
Through our analysis, we gained deeper insights into the evolution of Chen Duxiu’s thoughts. In his early writings, Chen was a fervent supporter of Western democratic ideals. However, his disillusionment with Western democracy, especially after the Treaty of Versailles, led him to co-found the Chinese Communist Party and embrace Marxist ideologies. Despite this shift, Chen’s later writings revealed a nuanced perspective. He criticized Stalin’s dictatorship and acknowledged the merits of bourgeois democracy, indicating an ambivalence toward both Western and Communist ideologies. This complexity in Chen’s thought underscores the importance of a refined approach in analyzing historical texts, which current AI models are still striving to fully achieve.
References
Reuse
Citation
@misc{chao2024,
author = {Chao, Anne S. and Zhong, Yi and Li, Qiwei and Liu, Zhandong},
editor = {Baudry, Jérôme and Burkart, Lucas and Joyeux-Prunel,
Béatrice and Kurmann, Eliane and Mähr, Moritz and Natale, Enrico and
Sibille, Christiane and Twente, Moritz},
title = {Efficacy of {Chat} {GPT} {Correlations} Vs. {Co-occurrence}
{Networks} in {Deciphering} {Chinese} {History}},
date = {2024-09-13},
url = {https://digihistch24.github.io/submissions/458/},
doi = {10.5281/zenodo.13907852},
langid = {en},
abstract = {We propose to examine the writing of the founder of the
Chinese Communist Party, Chen Duxiu (1879-1942), by using the
innovative AI technique ChatGPT. We intend to leverage ChatGPT to
detect change in Chen’s thinking about politics, specifically on his
thoughts about capitalism and communism. The central objective is to
compare the efficacy of our 2021 work on co-occurrence network
methodology with the novel ChatGPT approach. We seek the best method
to trace Chen’s ideological evolution – from an early advocate of
Western-style democracy to a proponent of Marxism and communism, and
to a final reckoning at the end of his life. Our tools include
ChatGPT, LLaMA, GPT-API, and Python. Early finding is that the
concept (topic-modeling) by GPT is accurate but constrained by word
limits. We will need more time to do a finer comparison. Our finding
is that Llamas with 2x7 billion parameters model is not adequate in
providing a summary, whereas ChatGPT-4 is strong is summarizing
straight-forward analysis, but would need more prompt engineering to
detect multiple and nuanced points of view. We offer two innovations
in this paper: 1) the utilization of advanced AI methodologies
grounded in extensive language models, as opposed to traditional
statistical techniques that often relied on oversimplified
assumptions, and 2) an extension of our analysis to sentences rather
than individual words, allowing for richer contextual
understanding.}
}